
In the ever-evolving landscape of digital marketing, staying ahead in the SEO race is not just about understanding your own website’s performance but also about comprehensively analyzing the competition.
This is where the strategic prowess of web scraping comes into play. It’s an ingenious tool that transforms how businesses approach their SEO strategies, turning data into a powerful ally.
As we delve deeper into the strategic value of web scraping in the world of SEO, we’ll explore how this method is revolutionizing the way businesses approach digital marketing.
Whether you’re a small startup or a large corporation, understanding and implementing strategic web scraping can be the key to unlocking your website’s full potential in the crowded digital marketplace.
What is Web Scraping?
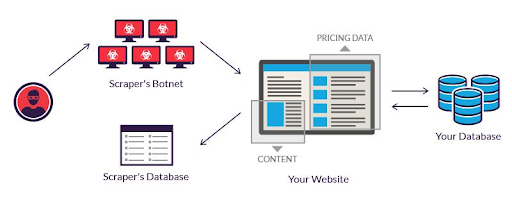
Web scraping is a technique used to extract data from websites. It involves sending requests to a website, getting the webpage’s response, and then extracting information from the HTML. The data can be saved in formats like CSV, excel, or databases, depending on what you need.
Web scraping has many uses. For example, businesses can gather market research or competitive intelligence. Researchers can scrape data for studies or analysis.
Web scraping is a powerful tool for collecting data, but it’s crucial to be ethical and legal in your approach.
Relevance to SEO
Web scraping is instrumental in SEO for various reasons. It helps in identifying keywords that rank above your web pages, uncovers competitors’ strategies, provides insights into the best-ranking content, and discovers backlink opportunities. This information is crucial for adjusting SEO strategies and improving website ranking on search engine results pages (SERPs).
Is Web Scraping Legal and Ethical?
Web scraping involves complex legal and ethical considerations. In the United States, scraping publicly accessible data has been deemed legal, but it depends on factors such as the nature of the data and the methods used.
Personal data and copyrighted content require caution and should be handled carefully. Legal aspects also include regulations like the California Consumer Privacy Act and contract law. It’s important to note that legal perspectives on web scraping can vary across countries, with the EU having its specific policies.
To ensure legal and ethical web scraping, it’s recommended to:
- Check the website’s Robots.txt file and Terms of Service.
- Avoid scraping personal data without a legitimate reason.
- Be cautious about scraping copyrighted data.
- Use proxies and anti-fingerprinting measures for anonymity.
- Limit data collection to what is necessary and avoid hoarding data.
- Extract only public data and seek permission if the data is confidential.
Although web scraping can be a lawful and ethical activity, it necessitates thoughtful deliberation regarding the data being scraped, compliance with applicable laws and regulations, and respect for the privacy and intellectual property rights of individuals.
What is SEO?
Search Engine Optimization (SEO) is a strategy used to improve website traffic from search engines. It focuses on getting more visitors without paying for ads.
When you search for something, you’ll see different results like images, videos, news, and more. SEO aims to make a website more visible in these search results so it can attract more visitors and potentially turn them into customers.
To do this, SEO considers how search engines work, the keywords people use, and which search engines are popular.
The process of SEO encompasses several key elements:
- Technical Optimization: This focuses on optimizing the technical aspects of a website to make it easy for search engines to crawl and index. It includes optimizing URL structure, site architecture, navigation, and internal linking. Factors like page loading speed, mobile-friendliness, HTTPS security, and structured data also play a role in technical SEO.
- Content Optimization: SEO requires optimizing content for both human readers and search engines. This means creating high-quality, relevant content that includes keywords used by the target audience. It should be unique, well-written, and up-to-date. Optimizing elements like title tags, meta descriptions, header tags, and image alt text is also crucial for search engines.
- Off-site Optimization: This involves activities that enhance a website’s reputation and authority, even though they are not directly related to its content or technical setup. Off-site optimization includes link building from relevant, authoritative websites. It may also involve brand marketing, public relations, content marketing, social media optimization, and managing online listings and reviews.
SEO is a dynamic field that evolves as search engines update their algorithms. It requires a combination of technical knowledge, content creation skills, and an understanding of online marketing strategies.
How to Enhance SEO Efforts through Web Scraping?
1. Competitor Analysis
Web scraping enables SEO professionals to collect and analyze data from competitors’ websites. This includes keywords, content strategies, backlink profiles, and other SEO-relevant information. Understanding competitors’ strategies can guide in refining one’s SEO approaches to stay competitive.
2. Keyword Research and Optimization
By scraping search engines and other platforms like forums and social media, SEO professionals can identify trending keywords, search volumes, and competition levels. This helps in optimizing website content and meta tags to align with search queries that users are actively using, thereby improving a site’s visibility in search engine results pages (SERPs).
3. Backlink Analysis
Web scraping can be used to identify backlinks pointing to a domain, helping to analyze the quality of these links. Quality backlinks from reputable websites can significantly boost a site’s ranking on SERPs, while links from spammy or irrelevant sites can be detrimental.
4. Content Strategy Development
SEO experts can develop a more effective content strategy by analyzing the best-ranking content in a specific niche or on competitors’ websites. Web scraping tools can identify what topics are trending, which types of content are performing well, and the gaps in the current content offerings.
5. SEO Audits
Web scraping aids in performing comprehensive SEO audits. By scraping a website, you can quickly gather data on various SEO parameters like page titles, meta descriptions, heading tags, and more. This helps in identifying and rectifying SEO shortcomings on a website.
Tools Utilizing Web Scraping in SEO
Many popular SEO tools utilize web scraping techniques to provide valuable insights to users. Here are some examples:
Ahrefs
A widely used SEO tool that leverages web scraping to provide data on backlinks, keyword rankings, and competitor analysis. It helps users understand the backlink profile of a website and identify opportunities for link building.
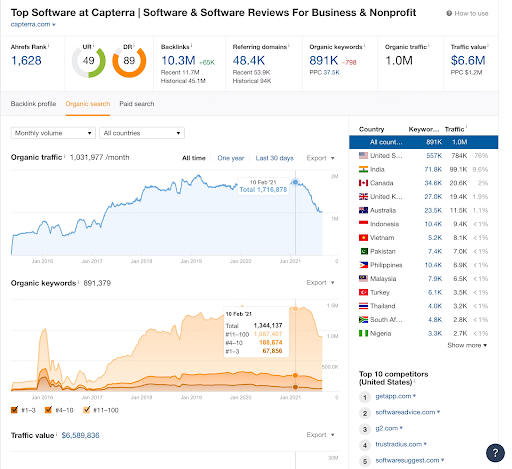
Semrush
Another comprehensive SEO tool that uses web scraping for keyword research, site audits, and competitor analysis. It provides insights into the strategies used by competitors, helping users optimize their websites accordingly.
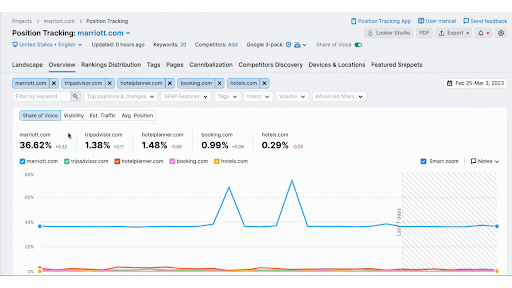
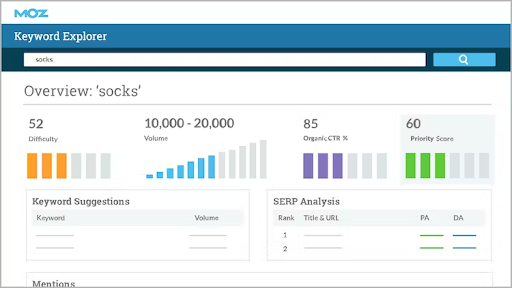
Moz
Offers a suite of tools for SEO, including link analysis, keyword research, and site audits. It scrapes data from the web to provide insights into various SEO metrics and recommendations for improvement.
How to Do Competitive Analysis Using Web Scraping
Competitive analysis using web scraping is a smart way to gain an edge over your rivals in the digital space, especially when it comes to SEO strategies. This approach involves extracting data from competitors’ websites to analyze their strengths and weaknesses.
1. Keyword Analysis
By leveraging web scraping techniques to extract data from competitors’ websites, you can gain valuable insights into the specific keywords they are targeting. This comprehensive understanding of their SEO strategy allows you to identify potential keyword opportunities for your website, enabling you to optimize your content and attract more organic traffic.
2. Content Strategy Evaluation
Through meticulous analysis of the type and frequency of content published by your competitors, you can uncover valuable insights into their content marketing strategies. By examining whether they prioritize blogs, videos, infographics, or other forms of content, as well as the frequency at which they update their content, you can shape your content strategy to effectively differentiate and stay ahead in the competitive landscape.
3. Backlink Analysis
Utilizing web scraping tools, you can gather data on the backlinks pointing to your competitors’ websites. This valuable information enables you to gain a deeper understanding of their link-building strategies, allowing you to identify potential link opportunities for your site. By strategically building high-quality backlinks, you can enhance your website’s authority and visibility in search engine rankings.
4. On-Page SEO Elements
By scraping on-page elements such as meta tags, headers, and image alt texts, you can gain valuable insights into how well-optimized your competitors’ pages are for search engines. This information allows you to benchmark their on-page SEO practices against your own, identify areas for improvement, and refine your optimization strategies to enhance your website’s visibility and relevance in search engine results.
5. Site Structure Analysis
A comprehensive understanding of how your competitors structure their websites provides valuable insights into their SEO priorities and user experience strategies. By examining their website architecture, navigation, and overall organization, you can gain inspiration for optimizing your own site’s structure, enhancing user experience, and improving your website’s overall search engine performance.
So, web scraping for competitive analysis can give you valuable insights into your competitors’ SEO strategies and help you improve your digital presence.
5 Common Challenges in Web Scraping
Web scraping, while a powerful tool for data extraction and analysis, comes with several challenges:
1. Dynamic Websites
Many websites use AJAX to load content dynamically, making them difficult to scrape using standard methods. Tools like Selenium and Puppeteer can be used to load such websites fully before scraping, but this process can be expensive and time-consuming, especially for large-scale scraping projects.
2. IP Bans and Blocking
Frequent and rapid requests to a website can result in IP bans. To prevent this, rotating proxies are often used to mask scraping activities. However, some sophisticated websites, including social media platforms, may ban IPs if certain conditions, like the absence of cookies in the request headers, are met.
3. Honeypot Traps
Some websites set up honeypot traps—decoy systems designed to attract and identify unauthorized scrapers. These traps can be in the form of links visible to bots but not to humans, leading to the scraper’s detection and blocking.
4. CAPTCHA and Anti-Bot Measures
Websites often implement CAPTCHAs and other anti-bot measures to differentiate between human users and automated scrapers. While there are tools and services to bypass these, they can slow down the scraping process.
5. Anti-Scraping Technologies
Companies like Imperva provide professional anti-scraping services, making it challenging for scrapers to access protected data. These services include bot detection and content auto-substitution techniques to prevent scraping.
Bypassing Imperva: Challenges and Ethical Considerations
Bypassing web scraping protections like Imperva can be both technically challenging and ethically complex, especially when considering SEO practices.
Imperva, a commonly used web application firewall, uses advanced methods to prevent unauthorized web scraping. To bypass these protections, web scrapers employ various techniques such as mimicking real web browsers, using headless browser automation, and utilizing behavioral analysis.
However, staying ahead of evolving anti-bot technologies requires continuous adaptation and updates.
Determining the legality and ethicality of web scraping depends on several factors:
- Terms of Use Compliance: It is important to check if web crawling or scraping is prohibited by the website’s terms of use.
- Copyright Considerations: You should determine if the website’s data is copyrighted.
- Potential Harm: Evaluating whether the scraping can cause material damage to the website or compromise individual or organizational privacy is crucial.
- Diminishing Value: Assessing if the scraping activity could devalue the service provided by the website.
In SEO practices, it is vital to maintain legal compliance and ethical behavior. This includes respecting website terms of service, using scraped data legitimately, and avoiding activities that could harm the website or compromise privacy.
Given the increased scrutiny on web scraping practices, it is essential to approach it carefully, balancing the need for data with respect for legal and ethical boundaries.
Remember that SEO professionals and organizations have the responsibility to ensure that their scraping practices align with legal standards and ethical norms.
How to Bypass Imperva?
To bypass Imperva‘s anti-bot technology, there are several methods you can employ. Here is a breakdown of each method and an explanation of how it helps you avoid detection:
- Use high-quality residential or mobile proxies: By using proxies, you can mask your IP address and make your requests appear as if they are coming from different locations. This helps to avoid being flagged as a scraper.
- Use HTTP2 (or later) version for all requests: Upgrading to the latest version of the HTTP protocol allows for faster and more efficient communication between your scraper and the target website. This can help prevent detection by Imperva’s technology.
- Match request header values and ordering of a real web browser: By mimicking the headers of a legitimate web browser, you can make your scraper’s requests appear more like regular user traffic. This can help evade detection by Imperva’s bot detection algorithms.
- Use headless browser automation to generate JavaScript fingerprints: Headless browsers, which can run without a graphical user interface, allow you to execute JavaScript code and generate unique fingerprints. These fingerprints can help your scraper appear more like a real user, making it harder to be detected.
- Distribute web scraper traffic through multiple agents: Spreading your scraper’s requests across multiple agents or machines can help distribute the workload and make the scraping activity appear more natural. This can make it more difficult for Imperva’s technology to detect and block your scraper.
It is important to note that Imperva continues to develop and improve its detection methods. Therefore, it is crucial to stay updated with the latest advancements in web scraping tools and libraries. For instance, you can explore the “Puppeteer stealth” plugin for Puppeteer, which keeps track of new fingerprinting techniques and helps maintain the effectiveness of your scraper.
Integrating Web Scraping Data into Your SEO Strategy
1. Keyword Research and Optimization
Web scraping helps gather data on popular keywords, search volumes, and competition levels. This data refines your keyword strategy to align with user search behavior and market trends.
2. Competitor Analysis
Scraping competitor websites reveals insights into their SEO strategies, including keyword usage, backlink profiles, content structure, and meta tags. Identifying gaps and opportunities for improvement allows you to compete effectively.
3. Backlink Opportunities
Scraping data on backlinks helps identify websites linking to competitors but not to you. Targeting these websites for your backlinks can improve your website’s authority and SERP rankings.
4. Content Strategy Development
Web scraping analyzes top-performing content in your niche, highlighting patterns in topics, formats, and engagement metrics. This data guides content creation for audience resonance and search engine ranking.
5. Real-Time Data Advantages
Scraping data in real-time enables agile adaptation to market changes, trending topics, and competitor actions. Capture traffic by quickly producing relevant content based on scraped insights.
6. Monitoring SEO Performance
Regularly scraping data allows monitoring of website performance, such as keyword rankings, site traffic, and user engagement metrics. Adjust your SEO strategy based on this data for continuous optimization.
7. Legal and Ethical Considerations
While scraping provides valuable insights, it’s important to scrape ethically and legally, respecting website terms of service and data privacy laws. Use scraped data responsibly to avoid harm or privacy violations.
Conclusion
Strategic web scraping is a powerful tool for maximizing SEO efforts.
By providing insights into competitors’ strategies, enhancing keyword research, bypassing challenges, upholding ethical practices, enabling real-time data analysis, integrating with SEO tools, optimizing content, making data-driven decisions, and offering a strategic advantage, web scraping empowers businesses to stay ahead in the competitive landscape.
With its comprehensive view and targeted approach, web scraping is an invaluable asset for businesses aiming to enhance their SEO performance.


